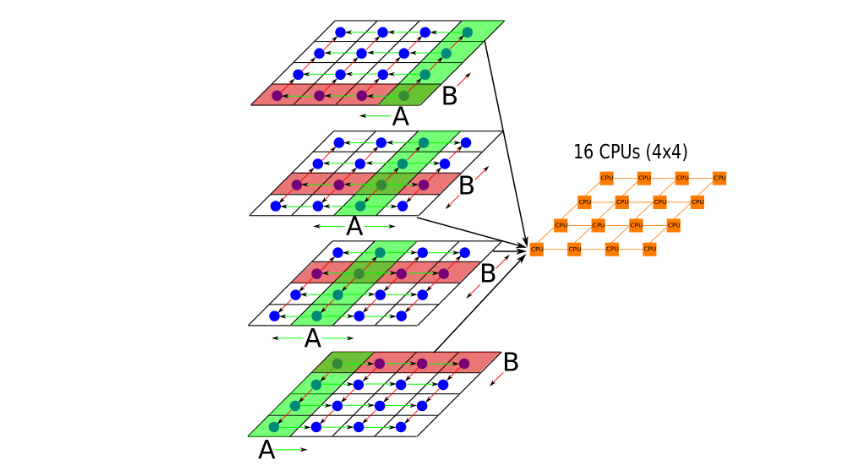
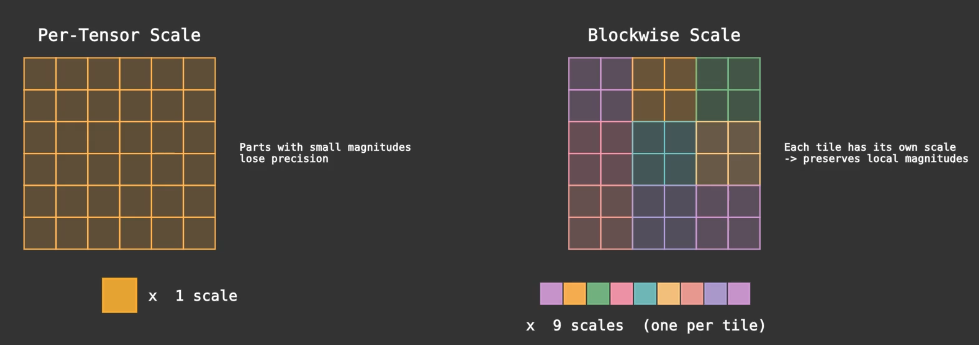
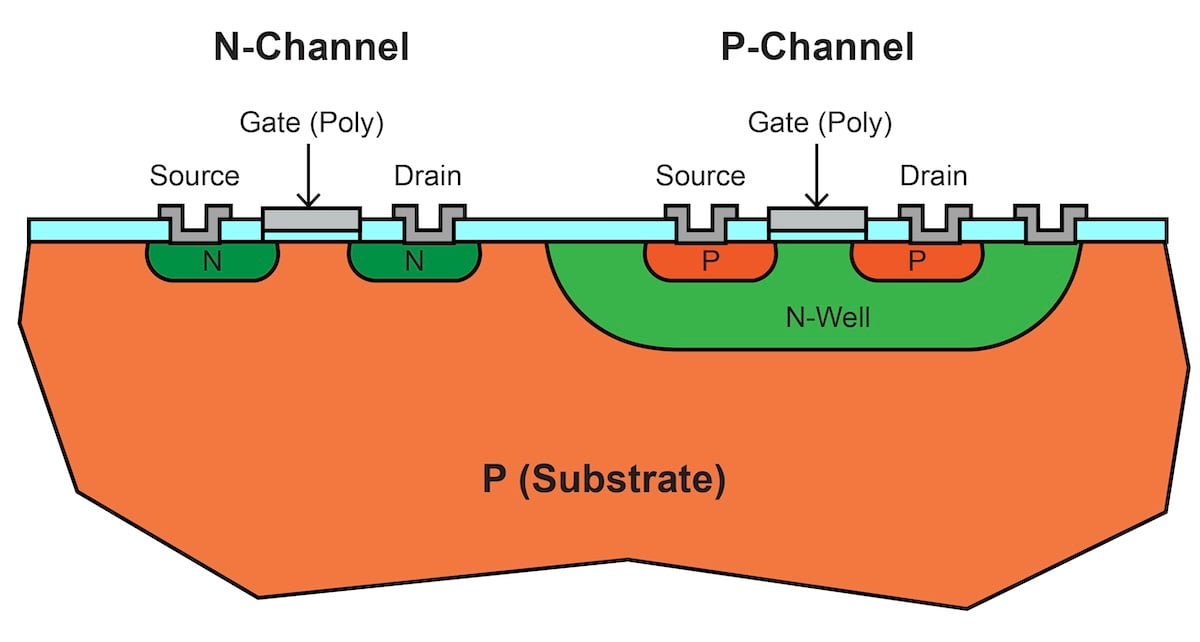
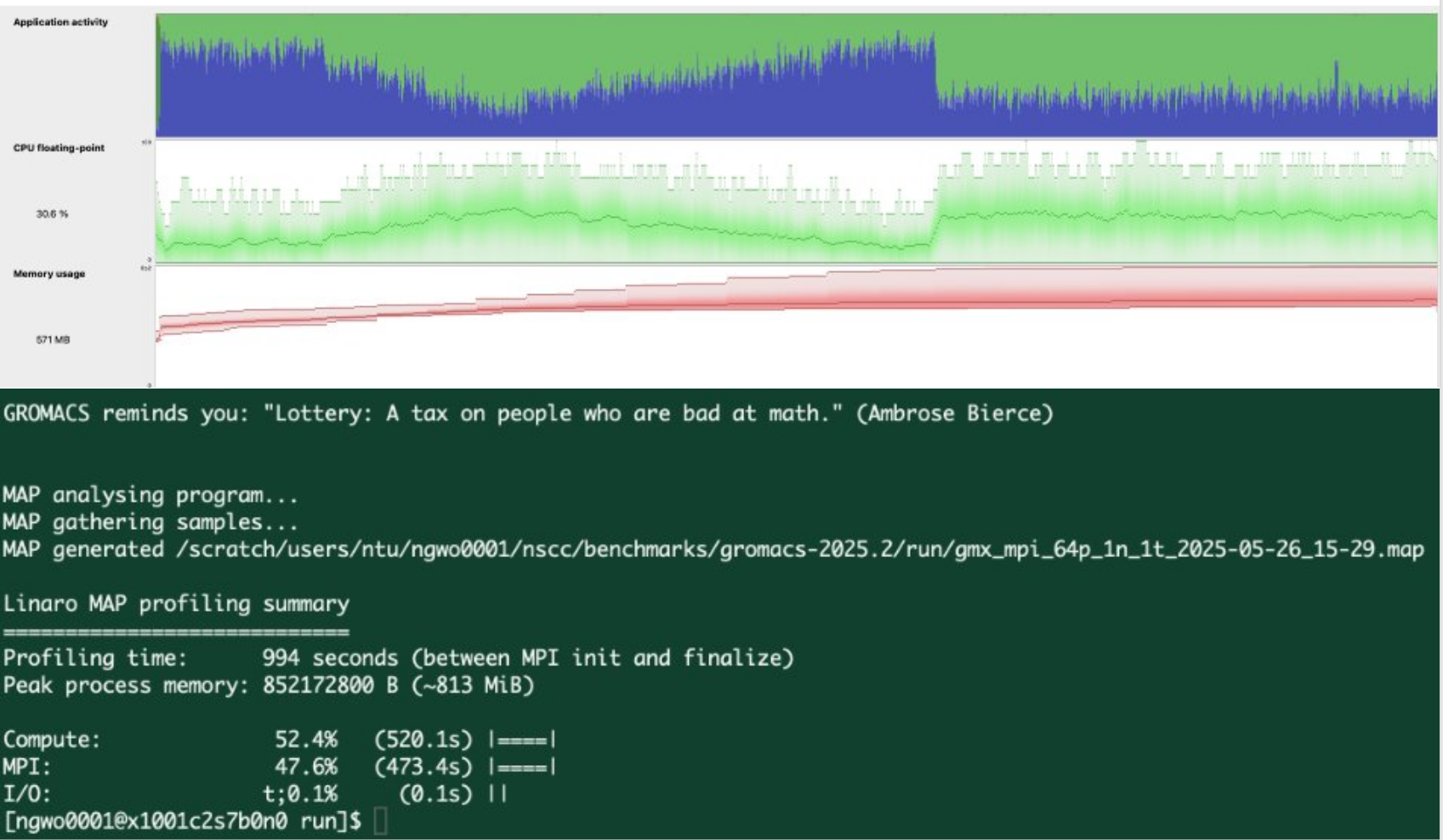
Scaling Distributed GEMM on Cerebras Wafer-Scale Engine
Scaling Distributed GEMM on Cerebras Wafer-Scale Engine In Large Language Model (LLM), the fundamental operations of transformer architecture are attention and multi-layer perceptron computation, both of which are built on a massive amount of GEMM (General Matrix Multiply) and GEMV (General Matrix-Vector Multiplication). During inference, the decoding step (specifically GEMV) is memory-bandwidth bound due to the LLM autoregressive nature. (i.e. the GPU, such as NVIDIA’s accelerator, spends most of its time loading data into the compute unit for a relatively little computation, which computes one new token per step....